Minecraft’s worlds may be “almost infinite,” but their generation is deterministic, meaning that with the right tools, we can reproduce them exactly. The catch? Doing it at scale is computationally brutal. This is the story of how I’m trying to bend that problem to my will with parallel computing.
Introduction
Minecraft is a voxel based sandbox game released in 2009. The game among its many unique traits, features an (almost) infinite procedural terrain generation system. The terrain generation system has evolved a lot over the years and now features three different dimensions. The terrain itself is divided into biomes which are “regions of world with distinct geographical features, flora, temperatures, humidities, and sky, water, fog, grass and foliage colors”.
Biomes
Biome generation is tied in to the world generation with quite a number of parameters determining the output. Minecraft world generation is deterministic and a seed can be specified during world creation. The same seed will always produce the exact same world every time. The number of distinct worlds possible it determined by the number of seeds. This number at the time of writing is the 64bit integer limit which is 18,446,744,073,709,551,616 (or 264) possible worlds.

Map Generation
Over the years people have been able to decompile the game and reverse engineer the world generation algorithm extensively. External tools such as Chunkbase are able to generate a biome map of the world given a seed. This is used both for finding a particular location within a minecraft world as well as in hobbyist seedcracking efforts where existing worlds are analyzed programatically to find the seed that generated them. Seedcracking is also used to locate worlds with special features in them, such as a 6 spawner dungeon.
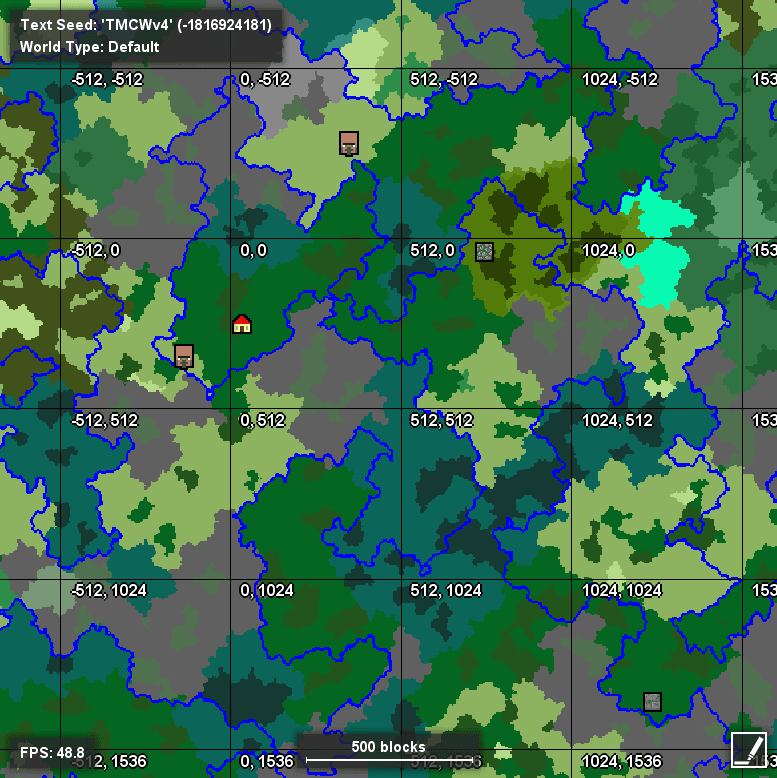
Chunks
Worlds in minecraft are built of blocks with the blocks being grouped into chunks. A chunk comprises of 16×16×384 blocks. A chunk is essentially the smallest unit of a loaded world. All blocks placed or destroyed are recorded as part of the chunk which is then saved and loaded from memory. This is done to improve performance as saving each block individually would be too taxing.

To generate a biome map of the world, biomes can be calculated on a chunk by chunk basis. However there is one caveat…
World
As mentioned earlier, a minecraft world is almost infinite. The “almost infinite” part might sound confusing. The reason behind this is that while mathematically there is no limit to how many chunks can be generated, we are limited by the limits of our computers. In earlier versions of minecraft (Pre Beta 1.8), terrain generation would break beyond 12,550,821 blocks from the origin due to floating point precision loss. This would lead to the noise generator breaking and generating the famous Farlands.

In Beta 1.8 this was addressed by shifting to a 64bit integer world generator and adding an impassable world border at 30million blocks from the world origin. So now the entirety of the playable world generates normally without glitches. These means that there are 14,062,500,000,000 ( a little more than 14 trillion ) chunks in a complete minecraft world. A fully generated minecraft world (with terrain) would take 409.2 petabytes to store.
Cubiomes
Cubiomes is a “standalone library, written in C, that mimics the biome and feature generation of Minecraft Java Edition”.
Benchmarking Performance
Using the following code to perform a million queries:
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <time.h>
#include "generator.h"
#define NUM_QUERIES 1000000
double now_sec() {
struct timespec ts;
clock_gettime(CLOCK_MONOTONIC, &ts);
return ts.tv_sec + ts.tv_nsec / 1e9;
}
int main() {
Generator g;
setupGenerator(&g, MC_1_21, 0);
applySeed(&g, DIM_OVERWORLD, 12345ULL);
// Random coordinate generation
int scale = 1; // block coordinates
int x, y = 63, z;
double start = now_sec();
for (uint64_t i = 0; i < NUM_QUERIES; i++) {
// Random x and z within a large range
x = rand() % 1000000;
z = rand() % 1000000;
volatile int biomeID = getBiomeAt(&g, scale, x, y, z);
(void)biomeID; // avoid optimization removing call
}
double end = now_sec();
double elapsed = end - start;
printf("Performed %d biome queries in %.3f seconds.\n", NUM_QUERIES, elapsed);
printf("Throughput: %.2f million queries per second.\n", NUM_QUERIES / (elapsed * 1e6));
return 0;
}I got the following results:
Performed 1000000 biome queries in 5.683 seconds.
Throughput: 0.18 million queries per second.That is obviously quite slow. Even thinking about generating the entire minecraft world with this is impractical without significant optimizations. To realistically handle world-scale generation, we’d need to leverage batch processing, multithreading, or even GPU acceleration to achieve acceptable performance. Otherwise, generating the entire world using this approach would take an infeasibly long time ( approximately 2.5 years of continuous computational time… yikes!).
My plan
Given the current performance limits of cubiomes, it’s clear that single-threaded generation won’t scale to the entire Minecraft world. Instead of chasing low-level code optimizations, I’m focusing on leveraging parallel computing to drastically boost throughput. My immediate goal is to implement MPI-based parallelism to distribute biome generation queries across multiple nodes on my university’s HPC cluster. This should provide a significant speedup by dividing the work efficiently.
Looking further ahead, I want to explore GPU acceleration through SYCL or CUDA, which could potentially offer orders-of-magnitude improvements by exploiting massive parallelism on graphics hardware. By combining these approaches, I hope to turn what would take years into something achievable within minutes or hours.
I’m also keeping the codebase modular and minimal to allow easy extension and experimentation. The current prototype supports overworld biome generation for Minecraft 1.21.0.
You can find the repo on my Gitlab:
Thanks for reading!
Until next time =)